Ôn tập Hệ tính toán phân bố - Một bước lên "mây"

Xin chào mọi người, giữ nguyên truyền thống mỗi mùa thi cuối kỳ, mình đã trở lại cùng một bài blog ôn tập mới với môn học NT533 - Hệ tính toán phân bố. Đây có lẽ sẽ là bài blog ôn thi cuối cùng của mình do hết môn để học trên trường rồi =))) Mình cùng vào nội dung chính luôn nhé!
Hình thức thi
Nội dung thi nói ngắn gọn thì sẽ là học hết. Còn nói dài hơn xíu thì thầy bên lớp mình có dặn như sau:
- Xem phần intro, các định luật (laws), clustering và grid.
- Cloud computing:
- IaaS: Virtualization of server, network, and storage
- PaaS: Azure (Case study)
- SaaS.
- Hadoop:
- MapReduce
- HDFS
- DFS
- HBase
- Sẽ có hỏi liên quan tới các bài tập trên lớp, các bài lab và tất nhiên sẽ có hỏi đồ án môn học.
Bài thi có thời gian làm bài là 90 phút và không sử dụng tài liệu (đề đóng). Trong đó:
- Trắc nghiệm từ 30-40 câu (6 điểm).
- Tự luận từ 2-3 câu (4 điểm), sẽ có một câu yêu cầu đề xuất giải pháp.
Ngoài ra, các bạn nào học hệ Chất lượng cao sẽ được ưu ái làm bài thi bằng tiếng Anh nhé.
I. Introduction and fundamental laws
Client-Server
A client-server system includes:
- One or more clients which use the services of the server (consumers).
- A server which provieds services (producer).
The connection will be established by the clients and the communication will work according to a protocol.
The client-server architecture consists of 2 layers and is called two-tier model.
For a distributed application, based on the client-server architecture, 5 tasks can be separated from each other:
- Display (graphical) UI
- Calculation of (graphical) UI
- Data processing
- Data management
- Data storage
According the their areas of responsibility, 4 types of clients exist:
- Text-Terminal or X-Terminal: Only task (1).
- Thin/Zero Clients: Task (1) and (2).
- Applet Clients or Network Computers: Task (1), (2), and a part of (3). The client process the applications themselves
- Fat Clients: Task (1), (2), and (3).
Một câu hỏi mình nghĩ có thể ra trong thi đó là hỏi xem thiết bị nào bên dưới thuộc kiểu X với X là 1 trong 4 kiểu client giới thiệu ở trên. Tuy nhiên khả năng thấp thôi do ví dụ trong slideset 01 nó khá cổ đại rồi.
Thin clients are better than fat clients in terms of cost efficiency mainly due to low power consumption. Let say we have a company running 500 computer and the electricity price is 0.32$ per kWh. We will calculate the electricity costs per year (including the leap year) for the two scenarios of using fat clients and thin clients.
Scenario 1: Fat clients
- Electrical power rating per PC: 450 watts
- Electrical power rating per screen: 80 watts
- Total cost is: $0.53kW * 24hours/day * 365.25day/year * 0.32 * 500 = 743,356.8$$
Scenario 2: Thin clients
- Electrical power rating per PC: 30 watts
- Electrical power rating per screen: 80 watts
- Electrical power rating per serrver blade: 600 watts
- Each server blade can handle 30 thin clients.
- Total cost for 500 thin clients: $154,281.6$$ (calculate the same way as fat clients)
- We need 17 server blades to handle 500 computer, so total cost for these are $28,612.23$$
- Add the two costs above and we get the final cost of $182,893.83$$
Nowadays, nobody uses Text-Terminal anymore, very few use Thin Clients, and Fat Clients are the standard for usage.
Fundamentals and Laws
There 3 options to reduce the time needed for solving the computation-intensive tasks:
- Optimization of algorithms used => They can’t be optimized infinitely.
- Use faster CPUs => This also can’t be increased infinitely.
- Add more computer system => Potentially unlimited but will be limited by the perfomance of the nodes, transfer rate of network and the maintenacne as well as administration effor for the connected system.
Moore’s Law
This is not a natural law but rather a rule, based of emprical observartion (nói trắng ra là quy luật tự suy ra từ thực nghiệm quan sát được). Originally, it was about electrical components of integrated circuit. Today, it is about the number of transistors.
The law: Basically, the number of transistors on a computer chip doubles roughly every two years (That’s it, really short).
Von Neumann Bottleneck
The data and control bus is increasingly becoming a bottleneck between the CPU and memory.
Take a look at the image below, the CPU needs both instruction and data from Memory Unit to function. But, these two flows share the same path, through the Bus System. Therefore, only one thing (instruction or data) can be transferred at a time. This causes waiting and when there’s too much waiting, it creates a bottleneck! (Nói chung đường thì chỉ có một lane nhưng cần tới 2 đối tượng đi qua đường nên anh này đi xong thì mới tới lượt anh kia. Nhiều anh đợi nhau lâu quá thì kẹt xe => bottleneck).
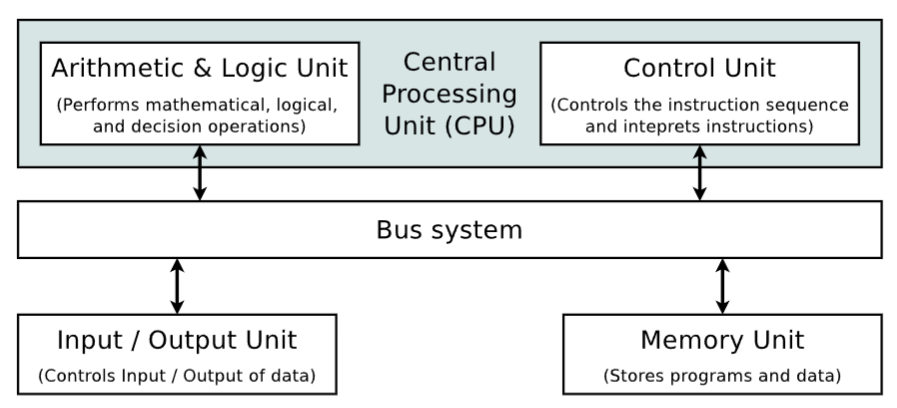
Caches can reduce the bottleneck impact because its is SRAM (Static Random Acess Memory), which has access speed close to the CPU speed. Where the main memory is DRAM (Dynamic RAM), which is slower.
If multiple CPUs (or cores) share the main memory => Bottleneck impact grows.
Amdahl’s Law
This law calculates the maximum expected acceleration of programs by parallel execution on multiple CPUs. The performance gain is limited mainly by the sequential part of the problem.
A program can never be fully executed in parallel i.e. initiallzation and memory allocation or if they depend on sequence of events, input-output and of intermediate results.
We define $P$ and $(1-P)$ as the parallel and sequential portion of the program respectively. With that, we have the total runtime of a program:
\[1=(1-P) + P\]If a program requires 20 hours of CPU time with a single CPU and in one hour, the process needs to run sequentially. The remaining 19 hours can be distributed to other CPUs for parallel execution. But, the total computation time can never fall under a single hour, not even with infinite number of CPUs
Thereby, we have the formula of:
\[S = \frac{1}{1-P+P/N + o(N)} \le \frac{1}{1-P}\]- $N$ = number of CPUs
- $P/N$ = accelerated parallel portion
- $S$ = SpeedUp factor or acceleration
- $o(N)$ = the load caused by communication and synchronization, it grows when N grows
Amdahl’s law does not take into account the cache and its effects. In optimial case where the entire data can be stored in cache (very rare), a super-linear SpeedUp may occur and leads to an acceleration greater than the additional computer power (S > p CPU cores).
A key takeaway from this law is: “With a growing number of CPUs, the problem size should grow too” => Gustafson’s Law.
Gustafson’s Law
This law says that “a problem, which is sufficiently large, can be parallelized efficiently”
Difference to Amdahls’ Law:
- The parallel portion of the problem grows with the number of CPUs.
- The sequential part is not limiting, because it gets more and more unimportant as the number of CPUs rises.
The formula is as follows:
\[S = (1-P) + N*P\]With this, if the number of CPUs grows to infinity, the SpeedUp grows linear with the number of CPUs.
Indentify the two laws
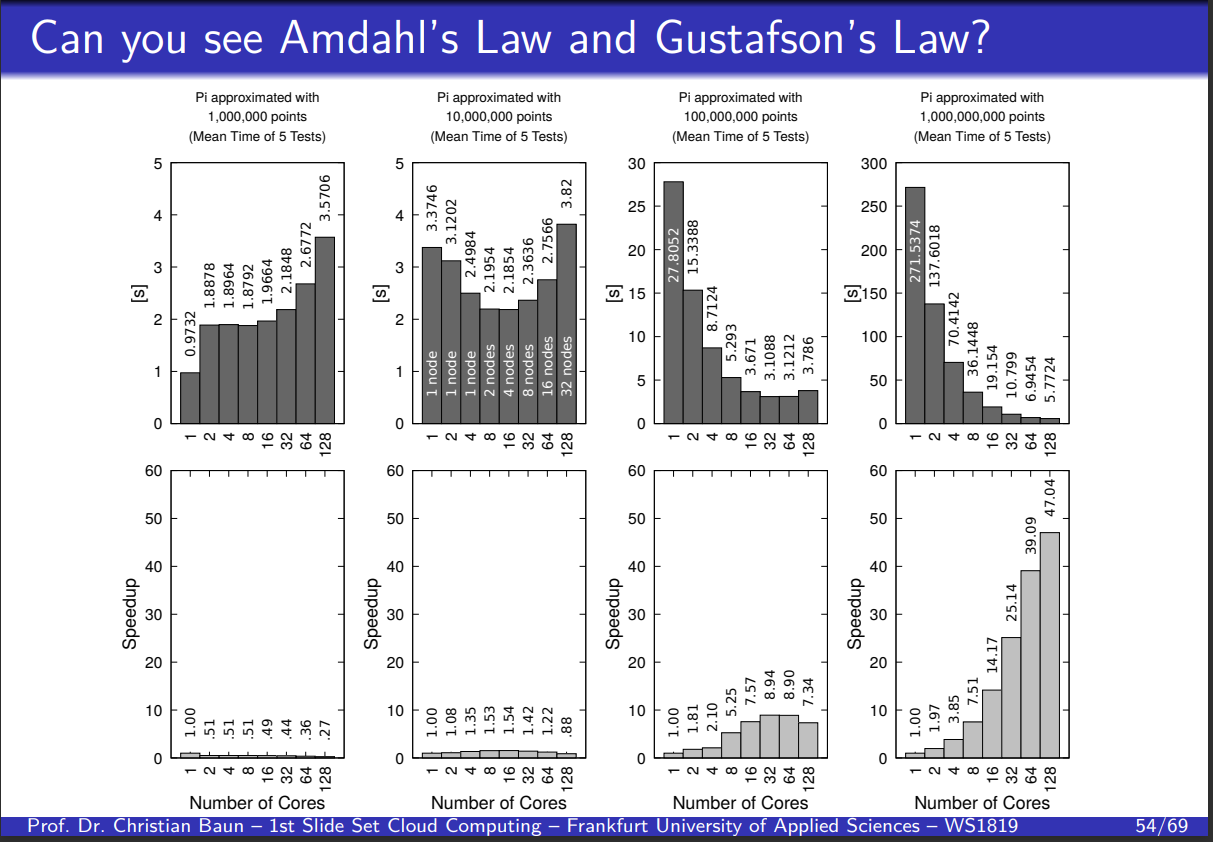
- Top Row: Illustrates Amdahl’s Law, showing diminishing returns on performance as the number of cores increases (Tăng số core CPU lên nhưng hiệu quả tăng ít hoặc thậm chí không cải thiện).
- Bottom Row: Illustrates Gustafson’s Law, showing more linear speedup with increasing cores for larger problem sizes (Problem càng lớn, sự hiệu quả khi tăng core CPU cũng lớn theo).
Từ đây thì mình nghĩ cũng có thể là một câu trắc nghiệm mà trong đó, người ta cho vài biểu đồ hiệu suất SpeedUp rồi hỏi mình nó đang theo Law nào.
Parallel computers
Sequential operating computers which follow the Von Neumann architecture are equipped with:
- A single CPU
- A single main memory for the data and the programs
For parallel computers, 2 fundamentally different variants exist:
- System with shared memory: The entire memory is part of a uniform address space, which is accessed by all CPUs. The memory is accessed via an interconnect
- System with distributed memory (a Cluster or Multicomputer): Each CPU can only access its own local memory. The communication between the CPUs takes place via a network connection (very slow). Every single CPU (and its local memory) is an independent node.
In shared memory system:
- Most multiprocessor systems today operate according to the symmetric multiprocessing (SMP) principle. This allows dynamically distributing the running processes to all available CPUs and they can acess the memory with the same speed.
- In asymmetric multiprocessing principle, each CPU must be assigned to a fixed task. Some run the OS, the remaining run the other processes.
II. Cluster.
Cluster definition
A cluster consists of at least 2 nodes. The nodes are connected via a computer network. Often, the nodes are under the control of a master and are attached to a shared storage.
From the user perspective, the cluster works like a single system => a virtual uniprocessor system (they don’t know it’s a cluster).
If the nodes are only available at specific times (working hours), the cluster is called Clusters of workstations (COWs) or Network of Workstations (NOWs).
Advantages:
- Flexibility and extensibility
- Lower purchase price campared with supercomputers
- Simple replacement of commodity hardware components
Drawbacks:
- Errors occur more often compared with a single supercomputer
- Clusters consist of many independent systems => Higher administrative costs
- High effort for distributing and controlling applications
Distinguishing Criteria of Clusters
Structure
- Homogeneous structure: One OS across the cluster
- Heterogeneous structure: Different OS in the cluster => A really bad idea, managing will be hell.
Installation concept
- Glass-house: The cluster is located in a single room or server rack => Better access and maintenance but in case of power failure, the entire thing goes down.
- Campus-wide: The nodes are located in multiple buildings and spread across the site of the research center or company =>Hard to fail completely but impossible to use high performance network between nodes.
Fields of application
- High performance (scalability): Achieve by redundancy of nodes, avoiding a single point of failure.
- High availability: It is not sufficient to use redundant nodes and redundant hardware inside the nodes; Uninterruptible power supplys (UPS) are require as well as protection against improper use, and sabotage. The availability of a system is calculate as follows:
- High throughput
Behavior in the event of failed nodes
- Active/Passive: During normal operation, at least a single node is in passive state (bro doesn’t do anything). If a node fails, the passive node takes over its services.
Active/Active: All nodes are in active state and run the same services. If nodes fail, the remaining active nodes need to take over their tasks.
Comparision between the two: A/P obviously doesn’t utilize all the available performance as some are passive nodes. Meanwhile, services in A/A must be designed for cluster operation because all nodes access shared data simultaneously.
Below is the classification of clusters, the A/P and A/A we have just discussed belong to HA clusters. We will go into more details of these cluster types in the subsequent sections.
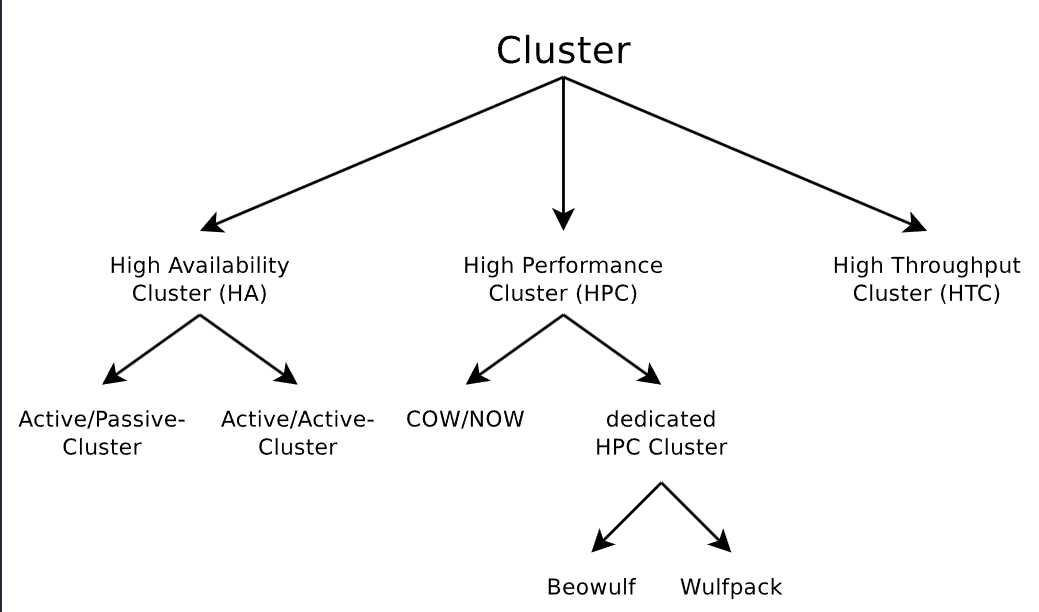
High Availability Clustering
Failover: Ability (usually provided by the OS) to automatically transfer the tasks of a failed node to another node for minimizing the downtime. Example: Heartbeat for Linux.
Failback: If failed nodes are operational again, they report their status to the load balancer and get new jobs assigned in the future.
The Split Brain problem: When communication between cluster nodes is severed, they enter a split-brain state. Each node is unaware of the others and believes itself to be the sole active node (primary node) in the cluster. This could lead to Data inconsistency, Reduced availability and Conflicting decisions.
There are 2 architectures of High Availability Clustering:
- Shared Nothing => Distributed Storage
- Shared Disk => Shared Storage
Shared Nothing
In a Shared Nothing cluster, each node has its own storage resource. Even, when a resource is physically connected to multiple nodes, only a single node is allowed to access it.
Advantage: No lock management is required, no protocl overhead and in theory, can scale in a linear way.
Drawback: Money for storage.
Distributed Replicated Block Device (DRBD), which operates at block level inside the Linux kernel, is a free software to build up a network storage for Shared Nothing clusters, without an expensive Storage Area Network (SAN). Shared storage is always a single point of failure, since only the cluster nodes are designed in a redundant way.
RBD can be used as a basis for:
- Conventional file systems, such as ext3/4 or ReiserFS
- Shared-storage file systems, such as Oracle Cluster File System (OCFS2) and Global File System (GFS2)
- Another logical block device, such as the Logical Volume Manager (LVM)
Shared Nothing with DRB:
- A primary server and a secondary server exist. Write requests are carried out by the primary server and afterwards are send to the secondary server. If the secondary reports successful writing, the primary reports the end of the operation.
- Practically, it implements RAID 1 via TCP. If the primary fails, the secondary becomes the primary.
- Read access is always carried out locally => better performance.
Shared Disk
In a Shared Disk cluster, all nodes have access to a shared storage. Some methods of connecting the nodes to the storage:
- SAN (Storage Area Network) via Fibre Channel: Expensive but high performance. Provides block-level access.
- NAS (Network Attached Storage): Easy to use, provides file system-level access, can be implemented as a pure software solution.
- iSCSI (Internet Small Computer System Interface): Use SCSI protocol via TCP/IP, provides SAN-like access via the IP-network
High Performance Clustering
Typical application area:
- Applications which implement the Divide and Conquer principle.
- Applications used for analyzing large amounts of data
Examples: Rendering a Pixar movie, flight path calculation, prime number computation, etc.
Advantages: Low price and vendor independence, easy to increase the performance in a short time via additional nodes, defective components can be obtained in a quick and inexpensive way.
Drawback: High administrative and maintenance costs, compared with mainframes
If a free operating system is used => Beowulf cluster. If Windows (paid and evil OS) => Wulfpack.
In Beowulf:
- It is never a cluster of workstations, nodes of a Beowulf cluster are used only for the cluster.
- The cluster is controlled via a master node.
- Worker nodes are only accessible via the network connection (no I/O devices)
- Worker nodes contain commodity PC components and are not redundant
High Throughput Clustering
Cluster consists of servers, which are used to process incoming requests, not used for extensive calculations (Tasks must not be split into sub-tasks).
Typical fields of application:
- Web servers
- Search engines
Large compute jobs => High Performance Cluster
Multiple small compute jobs (in a short time) => High Throughput Cluster
Libraries for Cluster Applications
Popular message passing systems:
| Parallel Virtual Machine (PVM) | Message Passing Interface (MPI) | |
|---|---|---|
| Purpose | Provides a uniform programming interface | Collection of functions to simplify development |
| Language support | C/C++ and Fortran 77/90 | Same as PVM |
| Environment | Heterogeneous | Homogeneous |
| Focus | Portability | Performance and security |
Đoạn này trong slideset 02 là có gần 30 slide nói chi tiết về code và function của MPI. Vì sức khỏe tinh thần, mình từ chối xem qua đống đó nên các bạn có thể tự tham khảo từ slide thứ 42 nếu muốn. Ở phần nội dung này mình nghĩ chỉ hỏi trắc nghiệm so sánh 2 bộ thư viện nói trên.
We also have Gearmean, a framework for developing distributed applications which supports C, Pearl, PHP, Python, C#, Java, .NET and UNIX shell.
- Assigns one of 3 roles to every computer involved:
- Clients transfer jobs to the Job Servers
- Job Server assign jobs of the clients to the Workers
- Worker register themselves at Job Servers and execute jobs

- Gearman should only be used in secure private networks since the communication is not encrypted (port 4730) and it has no mechanism for the authentication.
- Clients and workers access shared data. Cluster file systems like GlusterFS or protocols such as NFS or Samba can be used.
III. Cloud computing
Definition
Cloud computing is the on-demand delivery of computing services – like servers, storage, databases, networking, software, analytics, and intelligence – over the internet (“the cloud”). Essentially, instead of having your own physical hardware and software, you rent virtual resources from a cloud provider.
The fundamental techonologies of cloud computing includes:
- Virtualization: An abstract, logical perspective of physical resources (hide away the physical hardware). Usually it is an abstraction for the four computing resources - Storage, Processing power, Memory and Network.
- Web services: enable weakly coupled, asynchronous and messages-based communication, based on HTTP and XML. Most popular applications for web services include:
- RPC - Remote Procedure Calls (nowadays, gRPC is the more popular choice),
- SOAP - Simple Object Access Protocol, XML based and the message is stored in the body of a HTTP POST request.
- REST - REpresentational State Transfer, request via HTTP interface for stateless communication.
Cloud computing is an umbrella term for different services as mentioned before. Each of these service should be defined via a service level agreement (SLA) and will be offered as a product to the customers. If the service is provided by the company’s own department => inhouse. If it is provided by an external provider => outsourcing
Types of cloud:
- Public Cloud: Customer and provider belong to different organizations (Outsourcing)
- Private Cloud: Customer and provider belong to the same organization. Costs are similar to a non-Cloud-based architecture
- Hybrid Cloud: Public and private Clouds are used together. A good example would be handling traffic load with public cloud but store data in your private cloud.
Cloud services if defined by their funcitonality:
- Infrastructure as a Service (IaaS)
- Platform as a Service (PaaS)
- Software as a Service (SaaS)
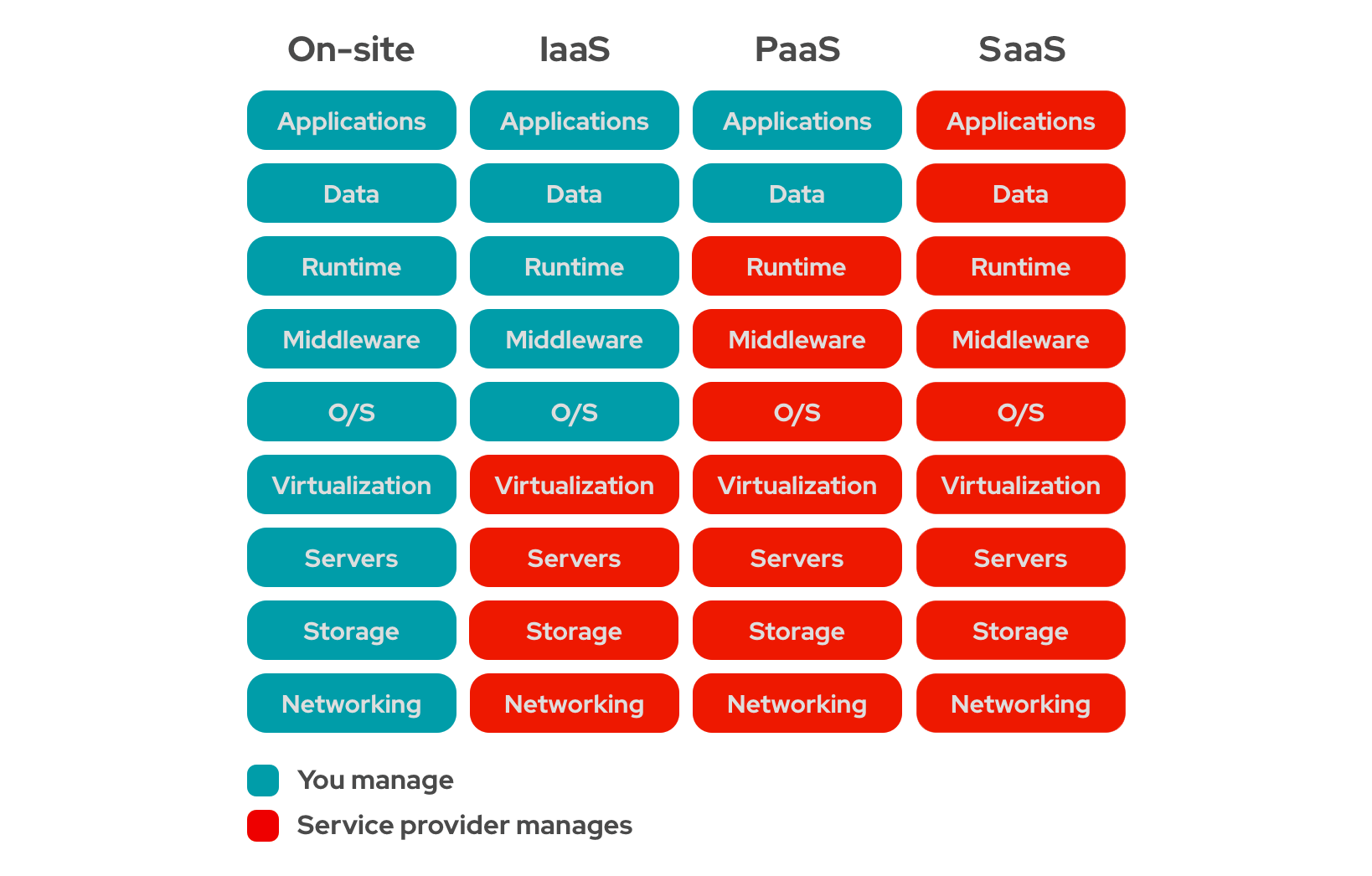
IaaS
Public Cloud and IaaS
Most common ones would be Amazon Elastic Compute Cloud (EC2), Azure Virtual Machine and Google Cloud Compute Engine. These services provide you with complete control of your computing resources and let you operate on their computing and infrastructure environment easily. It reduces the time required for obtaining and booting a new server’s instances to minutes, thereby allowing a quick scalable capacity and resources, up and down, as the computing requirements change. They offer different instances’ size according to the CPU and memory needs of the customers.
Private Cloud and IaaS
A private cloud aims at providing public cloud functionality, but on private resources, while maintaining control over an organization’s data and resources to meet security and governance’s requirements in an organization. The solutions for running private cloud infrastructure services that we will be looking at are Eucalyptus and OpenStack.
Eucalyptus - Elastic Utility Computing Architecture for Linking Your Programs To Useful Systems
It allows execution and control of virtual instances (Xen or KVM) on different physical resources and is compatible with AWS (EC2 + EBS + ELB + AutoScaling and S3).
It consists of several UNIX services:
- Cloud Controller (CLC)
- Cluster Controller (CC)
- Node Controller (NC)
- Walrus (like Amazon S3).
- Storage Controller (SC) The services communicate via web services (SOAP+REST)
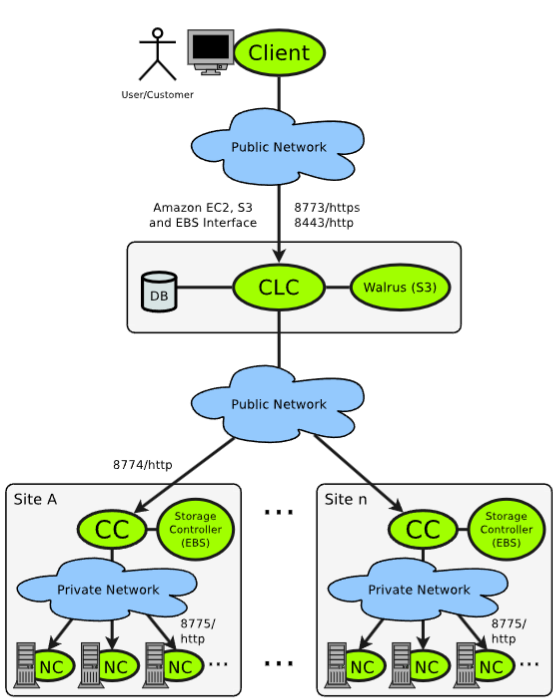
The NC runs on every physical node and controls the KVM hypervisor (Xen is not supported anymore since v4.0). Each NC transmits information about the utilization of their own resources to the CC of the site: Number of processors, free memmory, free storage.
Exactly a single CC per site is required. It controls the distribution of the virtual machines to the NCs. In each site, the NCs communicate with the CC via a virtual network (VLAN).
Exactly a single CLC per Eucalyptus infrastructure is required. It acts a meta-scheduler in the cloud infrastructure and collect resource information from the CCs. It runs on the same server as Walrus and SC.
Mr. Walrus uses S3 REST API and usually store images (object-based storage). It is not a distributing service and only operates in single-node mode. Replace this guy with Riak Cloud Storage for better performance.
If the infrastructure contains multiple sites, each site has its own storage controller which implements the EBS API.
To launch an istance in Eucalyptus, you need to provide the CLC with three parameters: Image, Instance type, and Number of instances. CLC will select a CC, then the CC will select one ore more NCs and then commands the start of the instance(s). If the image is not available on the NC, the NC requests the image from the CLC. The CLC transmits the image from Mr.Walrus via SCP to the NC.
Some not-so-fun facts about Eucalyptus:
- Installation is best done on CentOS or Red Hat Enterprise Linux. Other distributions will be a nightmare.
- Stable operation of Eucalyptus require lots of admin effort and commercial support (Skill issue and money issue).
- The source code is horrendous and the devs will not assist you.
- It got dumped by NASA in 2010 because it’s bad. The NASA engineering team went on to build Nova, which is now part of the best boi OpenStack
OpenStack
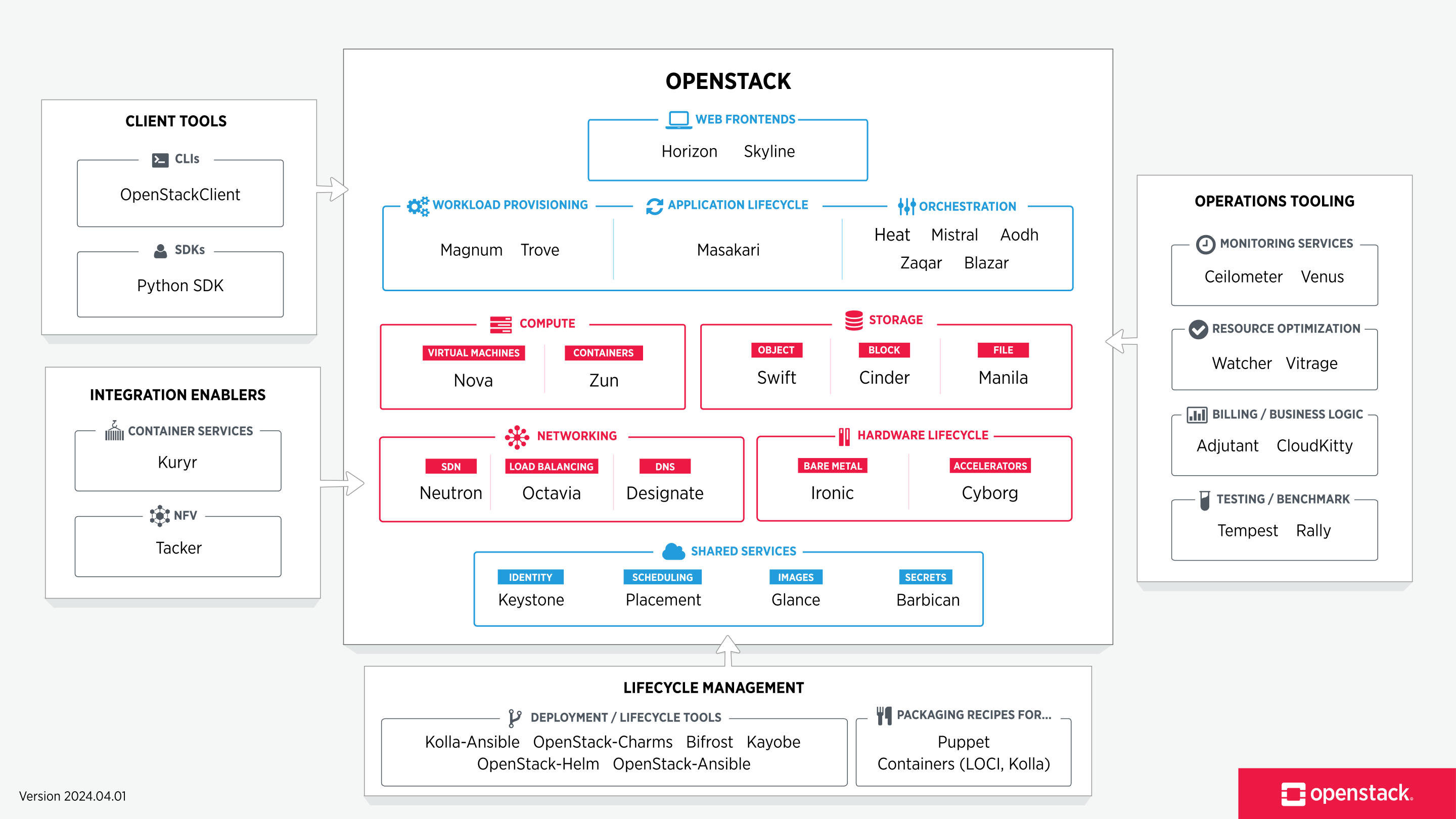
Contains several services which communicate via REST (so no SOAP).
- Compute with Nova: Implements the EC2 API, highly scalable.
- Object Storage with Swift: Implements the S3 API, redundant, highly scalable and allows automatic replication when nodes fail or are added.
- Image Service with Glance: Service for the search, register and request of images. Formats supported: Raw, AMI, VHD (Hyper-V), VDI (VirtualBox), qcow2 (Qemu/KVM), VMDK and OVF (VMWare).
- Block Storage with Cinder: Virtual storage devices can be created, erased, attached to and detached from Nova instances, implements the EBS API.
- Networking with Neutron: Service for managing IP addresses and distributing them to instances.
- Dashboard with Horizon: Provides a graphical web-interface for administrators and users.
- Identity Service with Keystone: Central directory of users for the other OpenStack services, provides user authentication.
PaaS
Platform as a Service (PaaS) is a computing platform that abstracts the infrastructure, OS, and middleware to drive developer productivity. It offer the right tools to implement and deploy hybrid clouds. They provide enterprises with a platform for creating, deploying, and managing distributed applications on top of existing infrastructures. They are in charge of monitoring and managing the infrastructure and acquiring new nodes, and they rely on virtualization technologies in order to scale applications on demand.
Azure case study
Windows Azure platform is one of PaaS vendors, based on .NET and Microsoft’s supported development tools. The platform is a group of cloud technologies, each providing a specific set of services to application developers.

Its major components:
- Windows Azure: Provides a Windows-based environment for running applications and storing data on servers in Microsoft data centers.
- SQL Azure: Provides data services in the cloud based on SQL Server.
- AppFabric: Provides cloud services for connecting applications running in the cloud or on premises.
Đoạn này trong Lecture 4 là có khoảng 90 slides để nói chi tiết về 3 component này của platform Windows Azure. Mình sẽ chỉ nói tóm gọn ở đây, khuyến khích các bạn xem thêm trong slide.
Windows Azure
- A foundation for Windows application on the cloud.
- Provides Windows-based compute and storage services. The running environment is IIS 7 and .NET.
- Compute:
- An app can have multiple instances, each is its own VM. Each VM is provided by a hypervisor (Hyper-V).
- There are two types of computation roles: Web role to interact with the user and Worker role to handle distributed tasks from the Web role. Any service must include at least one role type.
- Storage:
- Provides three type of storage: Blob for block storage to store text or binary file, Table for structure-based storage, and Queue for slices storage that support communication between applications.
- Blobs are stored in containers, there are two types of Blob: Block Blob with segment Read/Write operation (max 4MB each block) and Page Blob with random Read/Write, indentify by range of up to 1TB (provided by the X-Driver).
- Table can be used as a lightweight database, every entry in a table has an indentifier which contains Account Key and Table Key. They also have Partition Key to specify same data on different partitions and Row Key for row data indentifying.
- Queue consists of slices, each slice contains 8KB data. A good example of queue is the data communication between the frontend and the backend of a web app.
- Fabric controller:
- Provides an automatic and autonomous way to manage resources as well as software configuration.
- Each VM has a Fabric Agent to report the status to fabric controller.
SQL Azure
It provides a cloud-based database management system (DBMS) and data-oriented services in the cloud. The SQL Azure databse is a relational database which supports the Transact-SQL language. The maximum size of a single database is 10 GB.
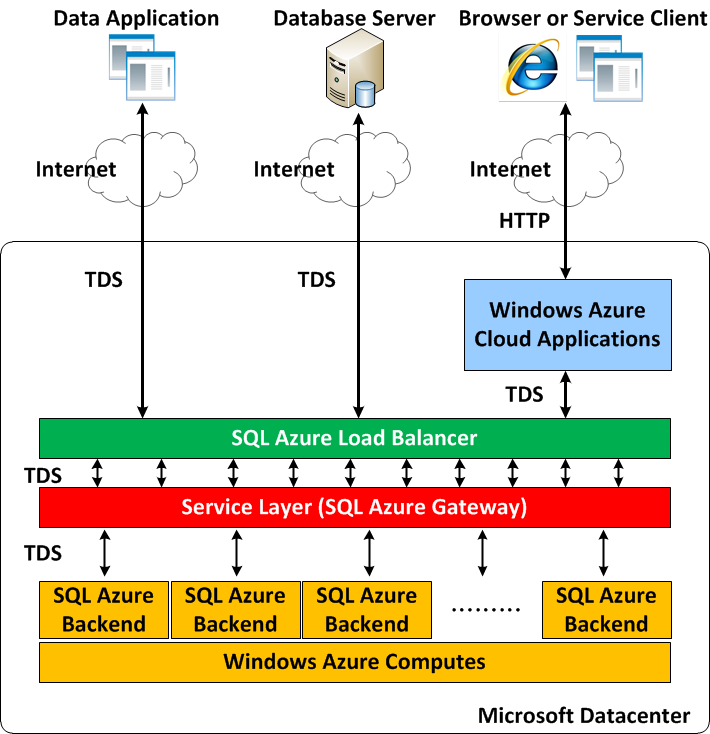
All communication uses the TDS protocol. Each connection between application and SQL Azure could link to different database servers => High availability.
The Gateway is the critical component which handles commands and accesses data. Connecting to the gateway can access all functionalities on SQL Azure.
In the Backend, SQL Azure Fabric manages databases that stores data in many SQL Azure nodes distributively. It also controls the policy and frequency of data replication.
AppFabric
It provides cloud-based infrastructure in connecting distributed services and applications. Basically, it establishes connections between applications. It has two components:
- Service Bus - Letting an application expose endpoints that can be accessed by other applications. Service Bus supports two types of communication mechanisms: Message Reply - The service bus sits between client and the server and Directly Connect - Probes a link for client to talk directly with the server.
- Access Control - Provides applications with authentication and authorization. It is a Single Sign-On (SSO) service for Service Bus, the user only needs a token when accessing multiple services.
FaaS
Function as a Service, a category of PaaS. Like the name suggest, it let client run their own functions without having to manage the underlying infrastructure. It can be also called serverless function because the backend is invisible for the customers.
These functions can be triggered by external request or events such as direct HTTP request, webhooks, MQTT events and so on. They can scale as well by running inside multiple instances.
Example of public FaaS: AWS Lambda, Google Cloud Function, Azure Function.
Example of private FaaS: Apache OpenWhisk and my beloved, OpenFaaS.
SaaS
Applications reside on the top of the cloud stack, users usually access them via web browser. It provides ready-to-run services that are deployed and configured for the user. In general, the user has no control over the underlying cloud infrastructure with the exception of limited configuration settings. A strong characteristic of SaaS services is that there is no client side software requirement. SaaS alleviates the burden of software maintenance for customers and simplifies development and testing for providers.
A few popular SaaS providers: Google Workspace, GitHub, Salesforce, Zoho, eyeOS, etc.
SaaS mình không thấy được nhắc tới quá nhiều trong slide lẫn sách tham khảo, có lẽ do nó đa dạng quá? Mỗi software có cấu trúc riêng và có hàng triệu software ngoài kia nên khó mà phân tích tổng quan được.
IV. Hadoop
Definition
Big Data is a collection of large datasets that cannot be processed using traditional computing techniques. It is not a single technique or a tool, rather it involves many areas of business and technology.
To handle this big boy, we need an infrastructure that can manage and process huge volumes of structured and unstructured data in real-time and can protect data privacy and security. For Analytical Big Data, there are sytems such as Massively Parallel Processing (MPP) database systems and Map Reduce algorithm.
This Map Reduce algorithm divides the task into small parts and assigns them to many computers, and collects the results from them which when integrated, form the result dataset.
Hadoop, the yellow elephant of evil, is an Apache open source framework written in Java that allows distributed processing of large datasets across clusters of computers using the MapReduce algorithm. It is essentially a distributed computing platform.
![]()
At its core, Hadoop has two major layers, namely:
- Processing/Computation layer (MapReduce)
- Storage layer (Hadoop Distributed File System)
HDFS
A Distributed File System (DFS) is a file system that allows files from multiple hosts sharing via a computer network. It supports concurrency and may include facilities for transparent replication and fault tolerance.
The Hadoop Distributed File System (HDFS) is based on the Google File System (GFS). Its main features:
- Support Petabyte size of data
- Heterogeneous - Could be deployed on different hardware
- Streaming data access via batch processing
- Coherency model - Write-once-read-many
- Data locality - “Moving Computation is Cheaper than Moving Data”
- Fault-tolerance
Architecture
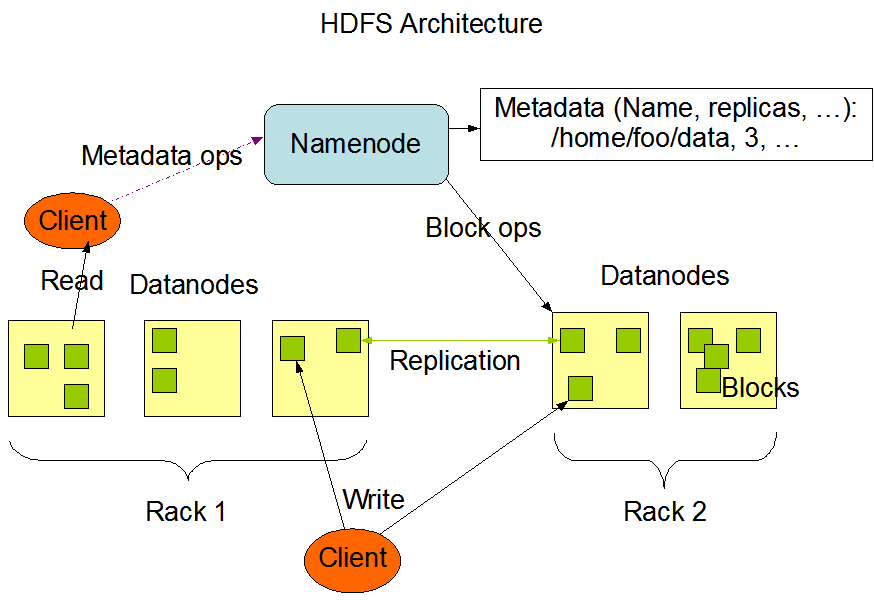
Namenode
Each cluster has one Namenode. This is the commodity hardware that contains the GNU/Linux operating system and the namenode software. The system having the namenode acts as the master server and it does the following tasks:
- Manages the file system namespace
- Regulates client’s access to files.
- Executes file system operations such as renaming, closing, and opening files and directories.
Datanode
Same hardware as namenode but runs the datanode software instead. For every node in the cluster, there will be a data node (n nodes => n data nodes). These nodes manage the data storage of their system. They perform read-write operations and also perform block creation, deletion, and replication according to the instructions of the namenode.
Block
The file in HDFS will be divided into one or more blocks and/or stored in individual data nodes. In other words, the minimum amount of data that HDFS can read or write is called a Block. The default block size is 64MB but this can be changed via configuration. All blocks in a file except the last block are the same size.
File System Namespace
Traditional hierarchical file organization, does not support hard or soft linking.
Implementation
Data (block) replication
- Blocks of a file are replicated for fault tolerance. The block size and replication factor are configurable per file.
- The NameNode makes all decisions regarding replication of blocks. It periodically receives a Heartbeat and a Blockreport from each of the DataNodes in the cluster. Receipt of a Heartbeat implies that the DataNode is functioning properly. A Blockreport contains a list of all blocks on a DataNode.
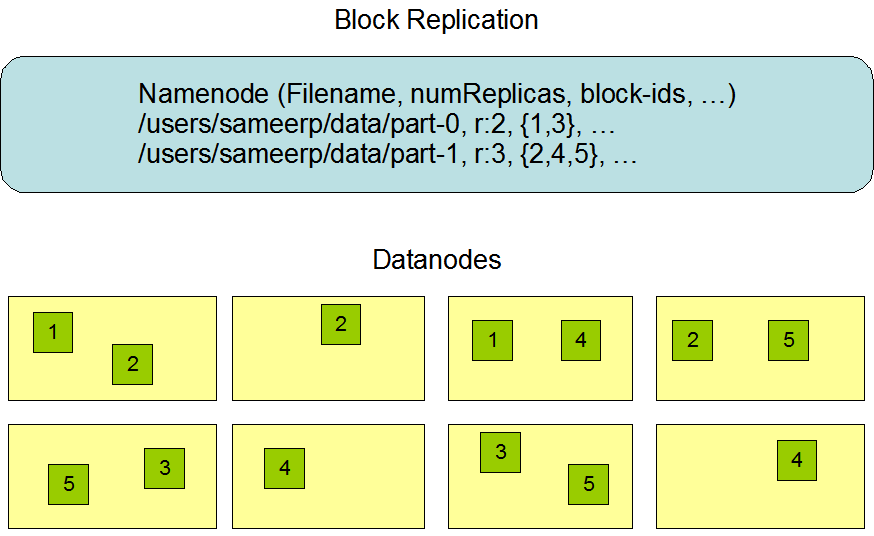
In the image above, the two commands specify that:
- Block of 1 and 3 in
../data/part-0need to have 2 replicasr:2, {1,3} - Block of 2, 4, and 5 in
../data/part-1need to have 3 replicasr:3, {2,4,5}
Replica Placement
It follows Rack-aware replica placement policy:
- Data reliability
- Availability
- Network bandwidth utilization
A simple but non-optimal policy is to place replicas on unique racks. This prevents losing data when an entire rack fails and allows use of bandwidth from multiple racks when reading data. However, this policy increases the cost of writes because a write needs to transfer blocks to multiple racks.
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on one node in the local rack, another on a node in a different (remote) rack, and the last on a different node in the same remote rack.
Data locality
Data locality in Hadoop is the process of moving the computation close to where the actual data resides instead of moving large data to computation. This minimizes overall network congestion. This also increases the overall throughput of the system.
Map Reduce
Map Reduce workflow
A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
The MapReduce framework consists of a single master JobTracker and one slave TaskTracker per cluster-node. The master is responsible for scheduling the jobs’ component tasks on the slaves, monitoring them and re-executing the failed tasks. The slaves execute the tasks as directed by the master.
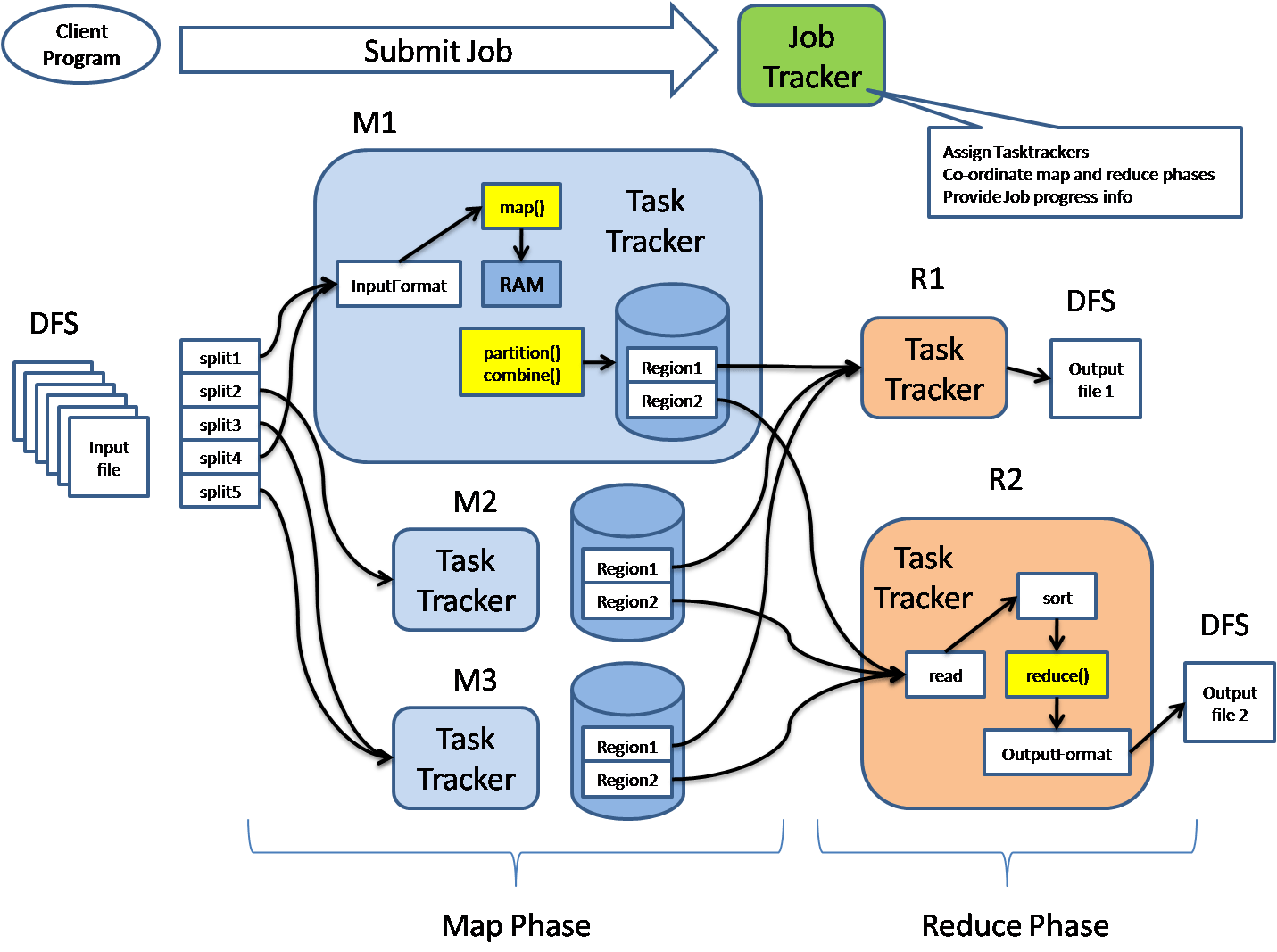
Minimally, applications specify the input/output locations and supply map and reduce functions via implementations of appropriate interfaces and/or abstract-classes. These, and other job parameters, comprise the job configuration. The Hadoop job client then submits the job (jar/executable etc.) and configuration to the JobTracker which then assumes the responsibility of distributing the software/configuration to the slaves (TaskTracker), scheduling tasks and monitoring them, providing status and diagnostic information to the job-client.
Summary: Application specifies information for input/output, etc => a Job, then submit this Job to the JobTracker. The JobTracker assigns TaskTrackers for the job execution. Now, the data of the job got splits into chunks and it goes through the Map phase then the Reduce phase.
Inputs and Outputs
The MapReduce framework operates exclusively on <key, value> pairs, that is, the framework views the input to the job as a set of <key, value> pairs and produces a set of <key, value> pairs as the output of the job, conceivably of different types.
Input and Output types of a MapReduce job:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
Wordcount example
The WordCount application is quite straight-forward, view source code here (You don’t need to understand the code, this section is only for explaining the workflow of MapReduce in more details).
Example input:
1
2
3
4
# File 1
Hello World Bye World
# File 2
Hello Hadoop Goodbye Hadoop
The Mapper implementation, via the map method , processes one line at a time, as provided by the specified TextInputFormat. It then splits the line into tokens separated by whitespaces and emits a key-value pair of < <word>, 1>.
For the given sample input the first map emits:
1
2
3
4
< Hello, 1>
< World, 1>
< Bye, 1>
< World, 1>
The second map emits:
1
2
3
4
< Hello, 1>
< Hadoop, 1>
< Goodbye, 1>
< Hadoop, 1>
WordCount also specifies a combiner. Hence, the output of each map is passed through the local combiner for local aggregation, after being sorted on the keys (Basically, if it’s the same word, combine them and value + 1).
The output of the first map:
1
2
3
< Bye, 1>
< Hello, 1>
< World, 2>
The output of the second map:
1
2
3
< Goodbye, 1>
< Hadoop, 2>
< Hello, 1>
The Reducer implementation, via the reduce method just sums up the values, which are the occurence counts for each key (i.e. words in this example).
Thus the output of the job is:
1
2
3
4
5
< Bye, 1>
< Goodbye, 1>
< Hadoop, 2>
< Hello, 2>
< World, 2>
In this example, the Reducer behaves the same as the Combiner.
Hbase
HBase is an open-source, distributed, non-relational database modeled after Google’s Bigtable. It consists of tables of column-oriented rows.
Hbase has easy integration with Hadoop MapReduce(MR) since the Table input and output formats are compatible.
Architecture
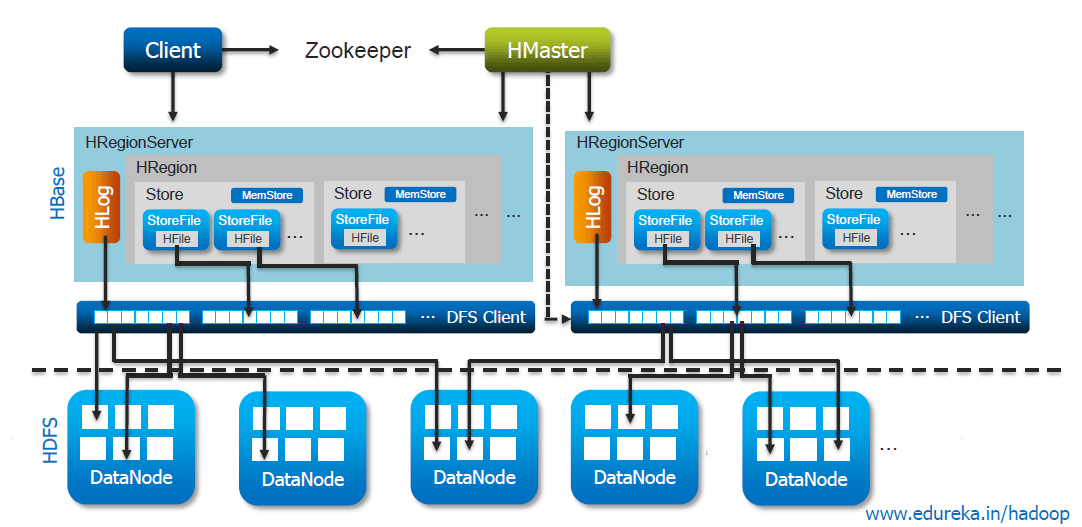
Key components:
- HMaster: This is the central coordinator in the HBase cluster. It manages the overall health of the cluster, assigns regions (data partitions) to Region Servers, and balances the load across servers.
- RegionServer (TabletServer):
- Serving Regions assigned to Regionserver
- Handling client read and write requests
- Flushing cache to HDFS
- Keeping Hlog
- ZooKeeper: This is an external service that provides coordination and distributed locking (Locate -ROOT-region) for HBase operations. It helps in master election and recovery.
- HDFS: All persistence Hbase storage is on HDFS(HFile, google Bigtable, SSTable). Hbase performnace is based on this guy’s performance.
In Hbase, Rows are stored in byte‐lexicographic sorted order and Tables dynamically split into “regions”. Each region contains values [startKey, endKey]
Data model

Data are stored in tables of rows and columns, where:
- Columns are grouped into column families. A column name has the form
<family>:<label>. Column family is the unit of performance tuning. - Rows are sorted by row key, the table’s primary key
- Cells are stored with timestamp for versioning.
(table, row, <family>:<label>, timestamp) ⟶ value
A table is viewed as a set of rows at the conceptual level. However, in physical view, a table is physically stored by the column family. If you want detail visuals, check out this website. To put it simply, conceptual view is just your normal table with all the columns for each entry. In physical storage view, it is split into groups of column family, that means if the data has 3 families, you will see 3 small tables , each show their own column content.
V. Nội dung khác.
Có một bài blog tổng hợp các câu hỏi về Apache Hadoop, các bạn có thể xem thêm tại đây.
Các chương nội dung trên mình vừa đi qua đã bao gồm hầu hết phần Lý thuyết của môn học này. Tuy nhiên, thầy nói sẽ hỏi nội dung liên quan tới các đề tài đồ án và tất nhiên, một bài blog nho nhỏ này không thể đi qua hết được. Dưới đây là một số link tài liệu của các đề tài mà mình chưa đề cập ở trên:
Mình không nghĩ là đề sẽ ác tới mức mà hỏi chi tiết những đề tài trên, nên chỉ đề cập ở đây để có thể coi sơ qua, biết nó là gì, cung cấp service nào.
Nội dung bài lab thì cũng có thể ra thi (không rõ nó như nào), tuy nhiên bài lab thì 2 công nghệ quan trọng nhất được học là Docker với Kubernetes rồi. Có thể cân nhắc xem thêm hai anh này để biết chúng làm gì.
Gần 90% là đề thi sẽ hỏi đồ án trong phần tự luận, riêng cái này thì bạn nào có đóng góp nhiều trong đồ án thì chắc không cần lo lắm, chỉ cần đọc lại báo cáo đồ án của mình là được. Một chuyện đáng quan ngại là có thể sẽ hỏi đồ án của nhóm khác nhưng nghe hơi vô lý nên chắc không có đâu…
Một câu tự luận cuối cùng đó là thiết kế giải pháp theo yêu cầu đề. Riêng câu này thì mình không có gì để chia sẻ rồi, nó phụ thuộc rất nhiều vào kinh nghiệm và kiến thức tổng quan của mỗi bạn để có thể đưa ra một giải pháp phù hợp cho vấn đề. Lời khuyên duy nhất là hãy chú trọng đến scalibilty, availability, security, và cost khi viết.
Bài blog tới đây là hết, cảm ơn tất cả những ai đã dành thời gian ra đọc tới đoạn này nhé. Chúc các bạn thi tốt!
Nguồn tham khảo.
- Slide môn học Hệ tính toán phân bố, UIT.
- Ebook Distributed system (4th): https://www.distributed-systems.net/index.php/books/ds4/
- Apache MapReduce Tutorial
- Apache HDFS Design